
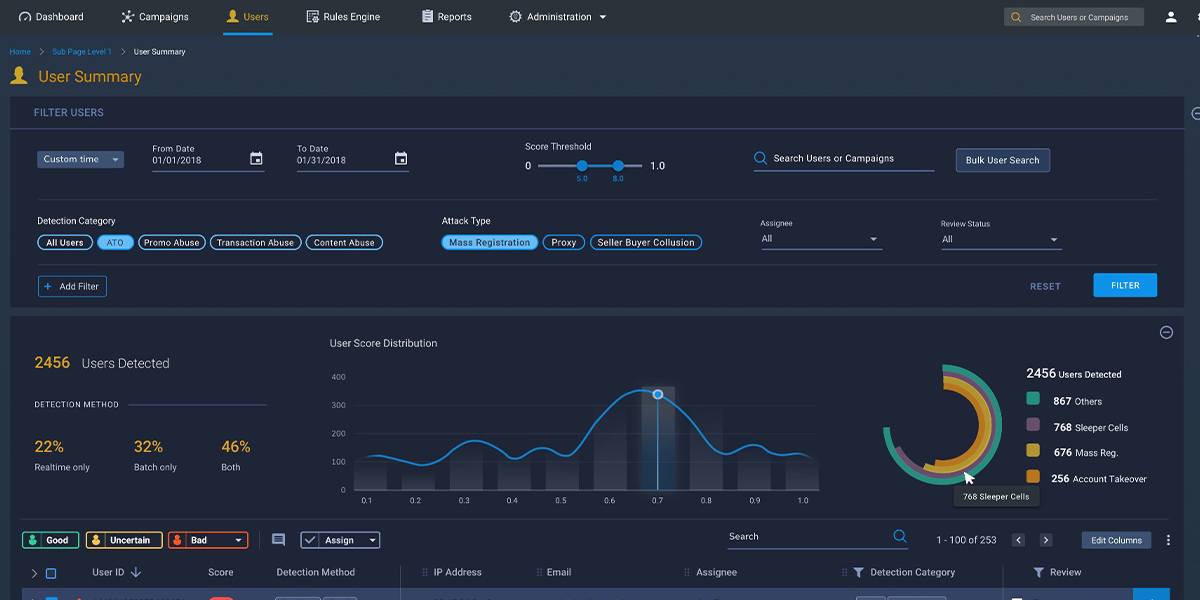
In this post, the second in our three-part series focusing on fraud modeling, we’re going to address the modeling process itself. We’ll begin by looking at some of the key pain points data scientists face when trying to build and deploy high-performance fraud models. The first, and perhaps most important, is domain expertise.
If you’re a data expert, then here is a question for you: How do you develop a great fraud model with only limited fraud expertise?
The ‘Kitchen Sink Model’
One answer is what Frank McKenna (Co-Founder and Chief Fraud Strategist for PointPredictive) calls the ‘kitchen sink model’:
“Building a fraud model without understanding the fraud business is what we like to call a ‘kitchen sink model.’ Throw every piece of data into the kitchen sink and just see what the model says. That just doesn’t work.”
As McKenna says, this approach doesn’t work.
Moreover, domain expertise is only one of the challenges data scientists face—speed is another. Building models is very time-consuming. Running a model with large datasets can take hours—if not days—and so does manually tuning and comparing models, especially when processing a massive number of cases.
Solutions for Fast and Comprehensive Model Building
The approach that does work is one that enables fast and comprehensive model building with automation and complete control.
Fast model building with automation
dCube, the groundbreaking new fraud management solution from DataVisor, offers a powerful “Auto Mode” for building high-quality initial models that are ready for deployment in a matter of minutes, instead of days. When running a model for the first time, weights are automatically computed for each feature, based on a combination of DataVisor’s domain expertise and the model’s advanced analysis of uploaded datasets.
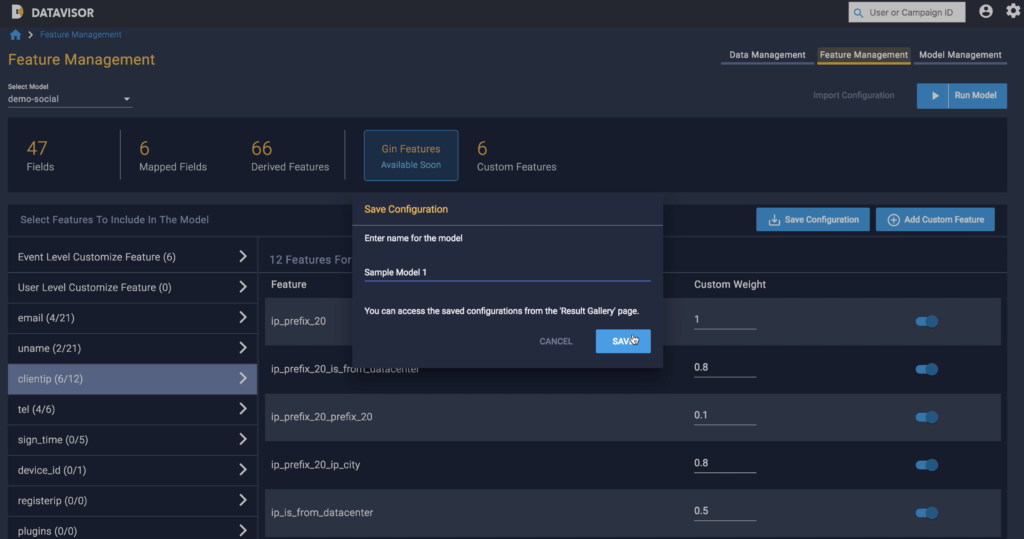
Comprehensive model building with complete control
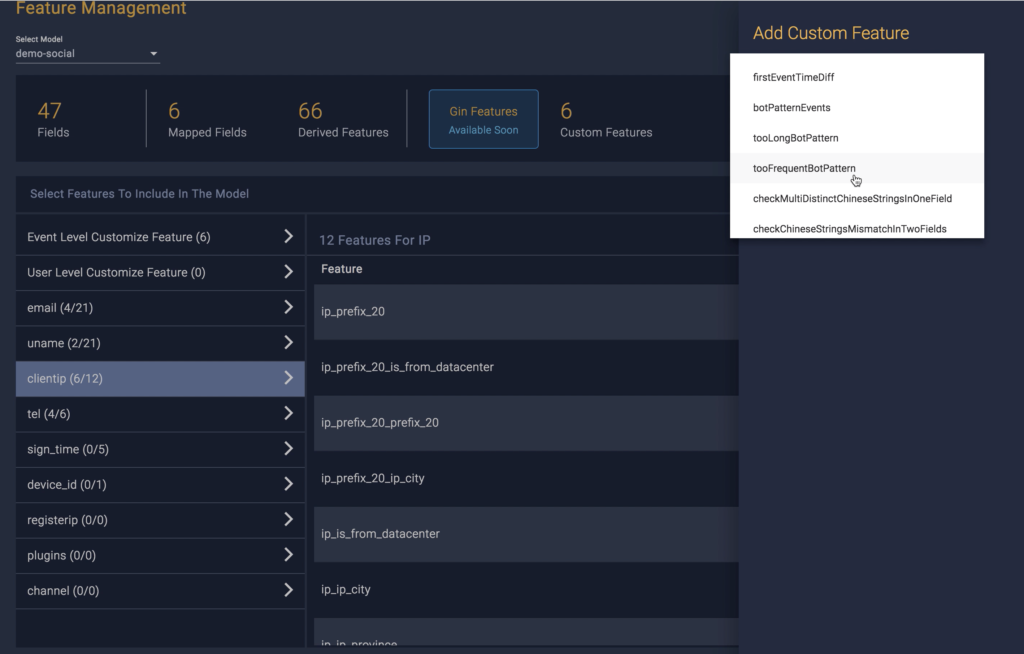
What does it mean to have complete control over the model building process? It means having the ability to override default recommendations at your discretion—and engineer custom features—based on your understanding of how different features best apply to your organization’s data. dCube enables you to select and deselect features, modify custom weights, and even create custom features using operators provided by dCube—including sophisticated logic operators.
As an example, dCube provides a pre-built operator—tooFrequentBotPattern—that can be used for detecting bot events that do not resemble human patterns.
Solutions for Efficient Model Validation and Comparison
One of the most impactful steps in the development of high-performance fraud models is validation—how well is your model working, and how confident are you in the results?
Advanced model validation for fast iteration
dCube provides you with a visualized Detection Summary that indicates how many clusters and accounts were detected by your model and offers additional statistics on precision and recall based on provided labels. Based on these results, it’s then easy to select your level of confidence by setting the threshold with a single click.
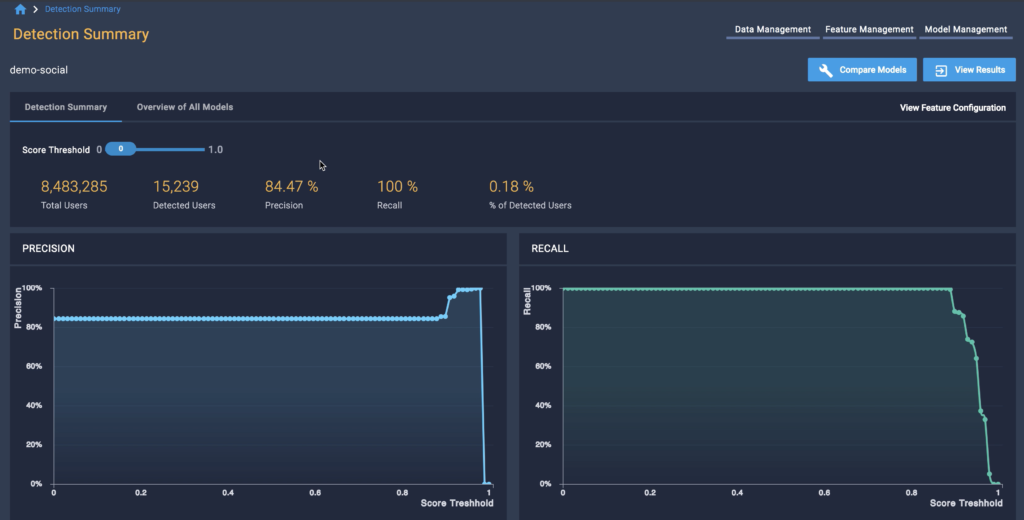
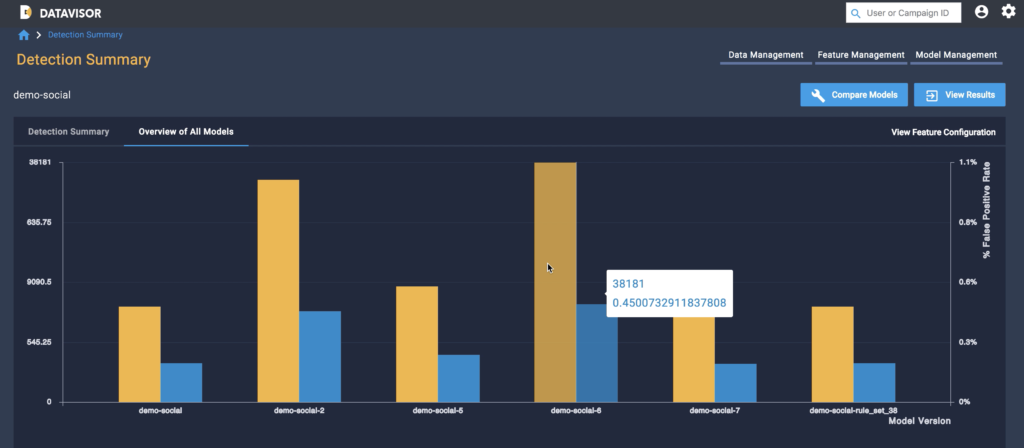
Building fraud models is an iterative process, and dCube helps you track the progress of iterated models over time. As you test and change parameters, dCube assesses performance and indicates whether performance is trending up or down—this enables you to fully optimize for wide coverage and high accuracy.
Cluster view for boosted efficiency
Legacy fraud detection solutions often necessitate that data scientists review every case individually. This is a time-consuming, inefficient, and ultimately outmoded approach. dCube, by comparison, provides a cluster view that enables fast review and labeling. Drawing on the power of proprietary unsupervised machine learning (UML) algorithms, dCube can detect suspicious accounts at the cluster level, uncovering correlated patterns that indicate coordinated activity by bad actors. Using cluster view analysis, users can label clusters of malicious accounts and apply bulk decisions with full confidence, boosting efficiency by as much as 100x. High accuracy is made possible by this holistic approach.
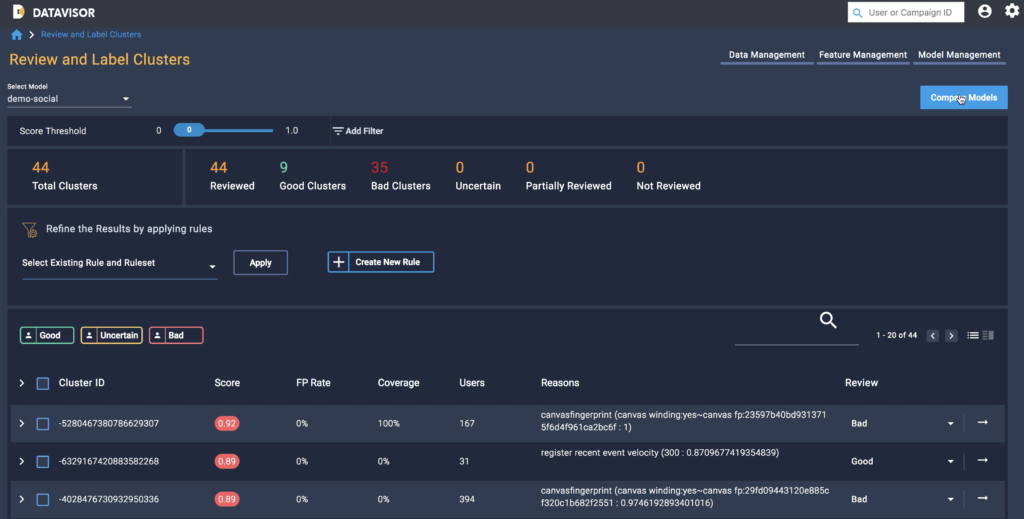
When data scientists do wish to dive deeper and investigate individual cases, they can simply click a given cluster to see individual level accounts and review digital fingerprints, user agents, time stamps, and device information, along with detailed reason codes and results.
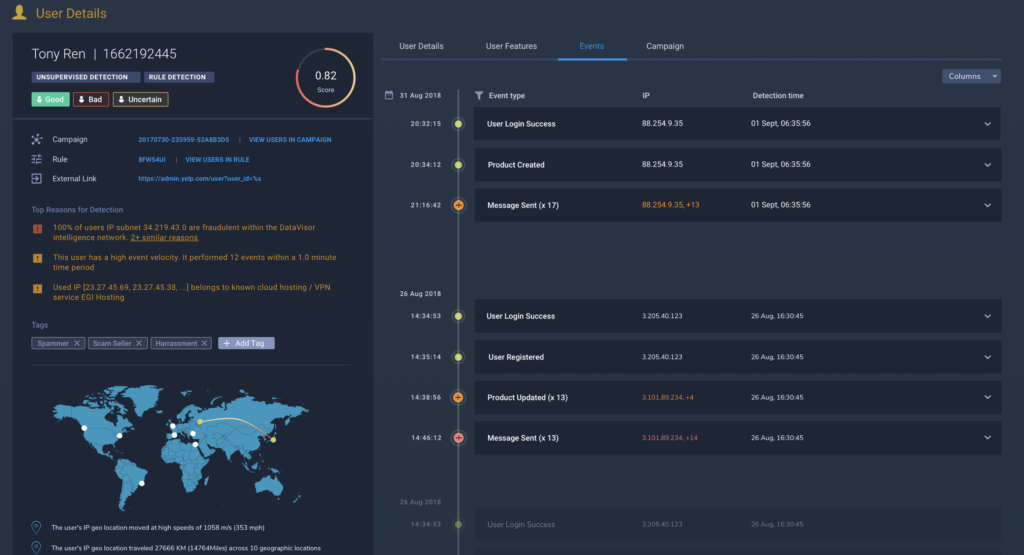
Auto tuning
dCube provides an automated solution for fast tuning. Users can simply label false positives and false negatives in the UI—or upload labels—and the model will adjust itself without the need to manually change parameters every time.
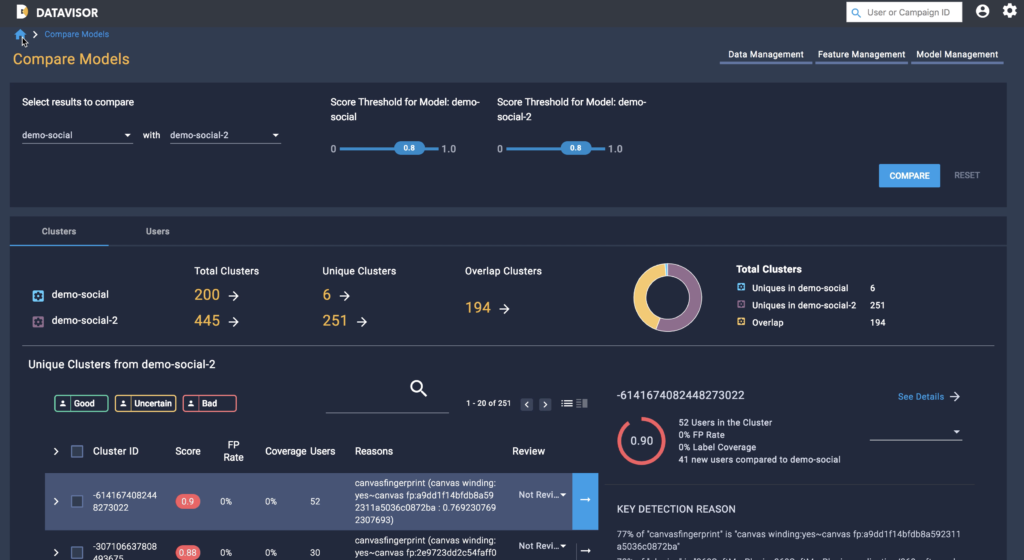
Cluster level model comparison
dCube allows users to compare model results by visualizing the number of overlap clusters across models, and the number of unique clusters in each cluster. Users can then make determinations as to whether those additional detected clusters are truly good or bad. In this way, users can confidently determine whether a new model has improved on its predecessor’s performance.
Seamless Collaboration Between Data Experts and Fraud Experts to Build Optimal Fraud Models
While data scientists may excel at building models, they may not necessarily possess the extensive fraud domain expertise required to build high-performing fraud-specific models.
dCube provides a unified platform that enables data scientists and expert fraud analysts to seamlessly collaborate early in the model building process—fraud teams can review detection results, assess model performance, leave comments, and label both cluster and individual users in the UI, and data scientists can immediately know what’s important and why. This kind of knowledge-sharing—when it takes place early in the model lifecycle—can significantly minimize retuning in the future.
Model Deployment
Data scientists can manage all existing models in dCube and see details and results for each version. They can quickly deploy or deactivate models within the UI and have the option to download full model documentation.
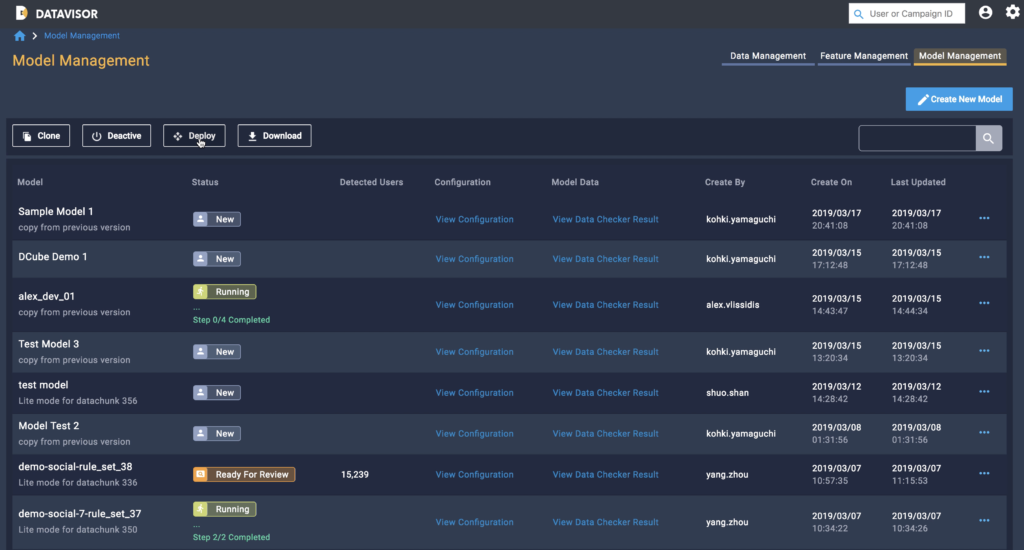
Information bottlenecks across multiple teams are counter-productive and should be eliminated. Fraud model building and deployment must be rapid enough to respond to fraud threats and abuse in real time. dCube facilitates collaboration between fraud and data science teams to build models, review detection results, compare models, improve performance, and deploy in production for significantly enhanced efficiency.
We’ve now covered pre-modeling and modeling. Please stay tuned for the conclusion of our three-part series, in which we’ll address post-modeling.



