
Introducing
Industry's first conversational AI agent that works across your entire fraud and AML workflows.
































.svg)
AI at the Core of Financial Crime Prevention
For more than a decade, DataVisor has pioneered the use of AI to protect global enterprises. Our platform unites adaptive AI agents, patented machine learning, and intelligent automation to help your team block new threats better and faster. The result is an unparalleled standard of defense — proactive, unified, and built for the future of fraud and AML.
Real-Time Protection Without Limits
DataVisor’s platform is engineered to keep pace with the largest and most complex financial ecosystems. Native, hyper-scalable infrastructure powers real-time AI decisioning with unmatched performance — so you can grow without fear.
30B+
15,000+
<100ms
Cloud-native
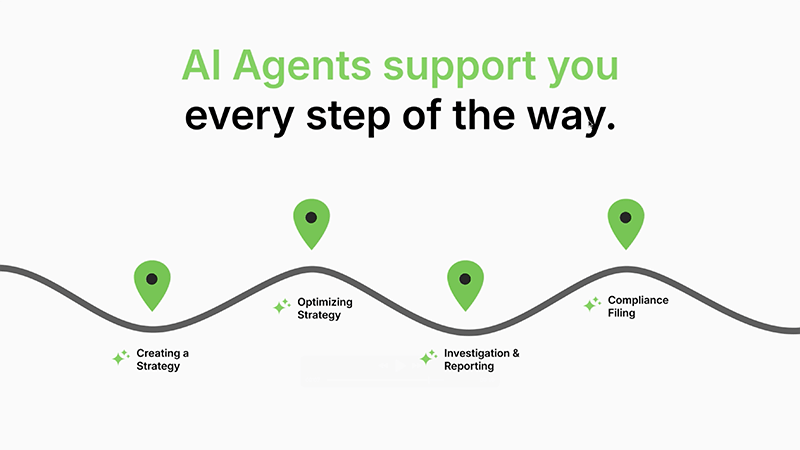
You’re Not Fighting Alone
You have DataVisor as your strategic partner, bringing you anonymized signals across industries, and a DEFEND community of fraud and AML leaders together to strengthen defenses as one.

.avif)
.avif)

Trusted by the World’s Leading Organizations
.svg)



.avif)


Awards & Industry Recognition
Year-After-Year,
the Industry’s Choice
Recognized by industry experts and praised by happy clients, DataVisor’s solutions deliver superior results.



.png)
.png)














Enterprise-Grade Security You Can Rely On
.svg)
.avif)


Helping you stay ahead

.svg)
.svg)
.svg)


The Dummy Handbook on Machine Learning for Fraud Detection
2025 FRAUD & AML EXECUTIVE REPORT Trends, Benchmarks...